Cognitive Computingの紹介(システム系論文紹介 Advent Calendar 2014)
はじめまして(の方が多いと思うので…)yasuharuと申します。
普段は組み込み関係、特にファームウェアの開発やLSI検証のお仕事をしています。よろしくお願いします。
半年ぐらい前の記事になりますが、こんな記事が発表されました。
IBM、新型「SyNAPSE」チップを発表--認知コンピューティングの可能性を広げる - CNET Japan
http://japan.cnet.com/news/service/35052072/
記事を見た時「脳型コンピュータチップってなんだろう?」という感じでした。
最初はちょっと目新しいだけなのかな…と思っていましたが、読み進めていくとこれはいけるんじゃないか?と思いました。
特にLSIの開発に関わっていると、LSIの微細化の問題などにより性能の頭打ちは顕著に感じられます。
これなら近い将来もさらに計算機の性能があげられそうです。
ということで、今回は上記の記事の全容を見るべく、Congnitive Computingがどういうアイディアを
元にしているか・どういう世界を描こうとしているか、論文とともに紹介をしていきたいと思います。
研究の概要
IBMのCognitive Computingに関する研究は、最初にサルの脳の情報伝達の考察から始まり、Neurocynaptic Chipの設計、
スパコンを使った性能シミュレーション、ASICでの試作、アプリケーションへの展開と着実に進化を遂げています。
これらの研究は2011年頃から発表されており、IBMのresearcherであるDharmendra S. Modha氏が中心となって進めているようです。
今回はこれらのうち、サルの脳の情報伝達の考察、ASICでの試作の部分を取り上げて行きます。
サルの脳の仕組みを追って
まずはNeurosynaptic Chipの目標とするアーキテクチャを見ていきます。
発想の原点となるのは、サルの脳の仕組みです。
Network architecture of the long-distance pathways in the macaque brain
http://www.pnas.org/content/107/30/13485.full
Macaqueは「東南アジア、日本、北アフリカに分布するオナガザル科マカク属(Macaca)のサルの総称 」です。
(引用元:http://eow.alc.co.jp/search?q=macaque )
CoCoMacというneurosynaptic database(脳の部位ごとの情報伝達などを扱っているデータベース)を元として解析・考察したものがこの論文です。
ざっくり言うと、この論文から以下の知見が得られたようです。
- 前頭葉が脳のネットワークの中心となること
- 各部位はある特定のコアを中心としてサブネットワークを構成する。そのコアを通して、全体のネットワークを構成する
このアイディアを元として、Neurosynaptic Chipの設計がされているようです。重要なのは、
- 特定の部位に処理が集中すること
- 複数のコアからなるサブネットワークが構成される。それらは階層構造を持つ
という2点です。
ちなみに、この論文、普段読むようなシステム系論文とは異なり、脳神経系の単語がバンバン出てきます。読むのが大変でした…。
ASIC化してみる
ASIC = Application Specific Integrated Circuit、つまり特定用途に特化したLSIです。
実際にLSIを作ってみましょうという話ですね。
一体どれだけのお金が…と言っても、自社のファブだから関係ないのかもしれません。
前置きはさておき、このASIC化について述べられた論文が以下のものです。
A 45nm CMOS Neuromorphic Chip with a Scalable Architecture for Learning in Networks of Spiking Neurons
http://www.modha.org/papers/013.CICC2.pdf
論文の前置きとして、一般的な脳の情報伝達はどうなってるのか?というのが少し書かれています。
これが肝になるアイディアなので、ちゃんと書いておきます。
(ただし、図はWikipedaから持ってきたもの、文章は論文からのものなので、図と文が一致しない部分があります。すみません、手を抜きました…。)
- 図は一つのニューロンを表す
- スパイク(spike、図中には記載なし)は、あるニューロンの軸索(axon)から発生され、他のニューロンの樹状突起(dendrite)に作用する(図は単一のニューロンですが、左右にニューロンがつながっていると思ってください)
- 軸索から樹状突起の接合部分をシナプス(synapse)と言い、スパイクを伝達するかどうかを決定する
- 各ニューロンは膜電位(membrane potential)膜電位を持ち、ある一定のスレッショルドを超えるとスパイクを発生させる
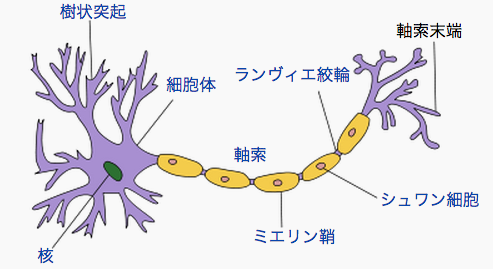
引用元:Created by Quasar (talk), http://ja.wikipedia.org/wiki/%E7%A5%9E%E7%B5%8C%E7%B4%B0%E8%83%9E#mediaviewer/File:Neuron_Hand-tuned.svg
このニューロンの構造を使って、Neurosynaptic Chipが作られました。このチップの特徴は以下のとおりです。
- 45nmプロセス
- 256のニューロン
- 64kbitのシナプス
この回路は次のブロック図で表されます。
先の図で言うところのシナプスに相当するのが256x256のSynapse Array、これを中心として、
軸索からシナプスを通って樹状突起に作用する一連の流れを表します。
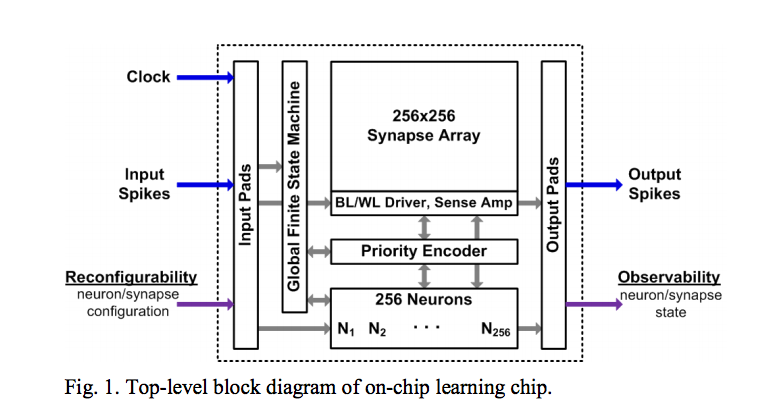
引用元:http://www.modha.org/papers/013.CICC2.pdf
外部からのスパイクを受けて、学習を行い、出力をします。特徴として、同じ構成のチップをたくさんつなげることで、スケールアウトが簡単にできます。
細かいニューロンの動きは今回は説明を省略させていただくとして、一番興味をもった部分は、Synapse ArrayのSRAMの構造です。
一般的なSRAMのトランジスタの構成は以下のとおりです。
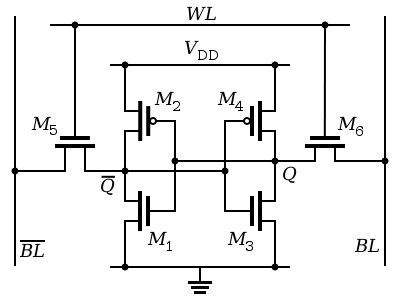
{kind=link}
.svg){kind=link}
しかし、今回の研究で使われているSRAMは以下の構造になります。
(図を読み解くヒントとして、下の図では値の記憶部分をインバータで表現していますが、上の図はトランジスタで表現しており、
これらは等価なものです。その点だけ気をつければ、違いは大きく一箇所のみです)
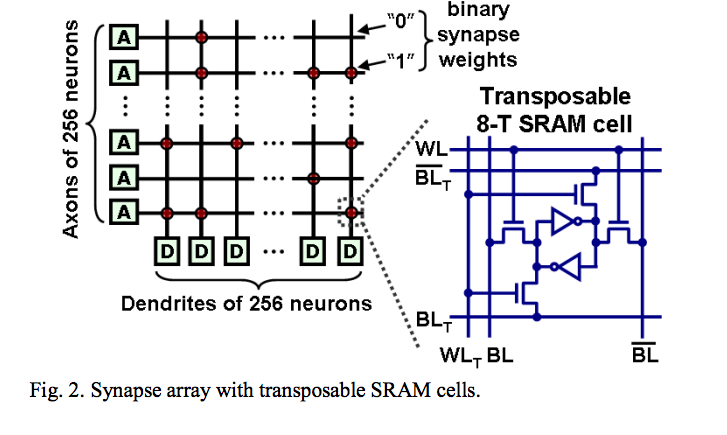
引用元:http://www.modha.org/papers/013.CICC2.pdf
要はrowとcolumn両方ともからread/write可能なSRAMになっています。
こうすることで、軸索(axon)に対応するrowの読み書き、樹状突起(dendrite)に対応するcolumnの読み書きを高速に行うことができます。
まとめ
ざっくりとした話で、サルの脳から始まるアイディアとASIC化について書いてみました。
まだまだアプリケーションレイヤーの話などもありますが、一つの記事には長すぎるのでこの辺りでいったん終わりとします。
最後にまとめようと思ったのですが、実はこれだけの論文を読んだだけだと「サルの脳」と「ASIC化」の関連性がさっぱりとわかりませんでした…。
サルの脳の話はなくても…?という感じがしますが、もう少し読み進めてみないとわかりません。
ということで、ちゃんと物語としてまとまっているのか? あるいは、試行錯誤の中で(サルの脳の話は)うやむやになっているのか、
この続きは(反応があれば)リアルな場で発表したいと思います。
それではみなさん、良いお年を!